



OneSource Cloud
April 28, 2026
15 min read
How to Build Private AI Infrastructure for Healthcare (2026 Guide)
Build private AI infrastructure for healthcare that actually holds up under audit.
Design, Deploy and Operate your Private AI Infrastructure
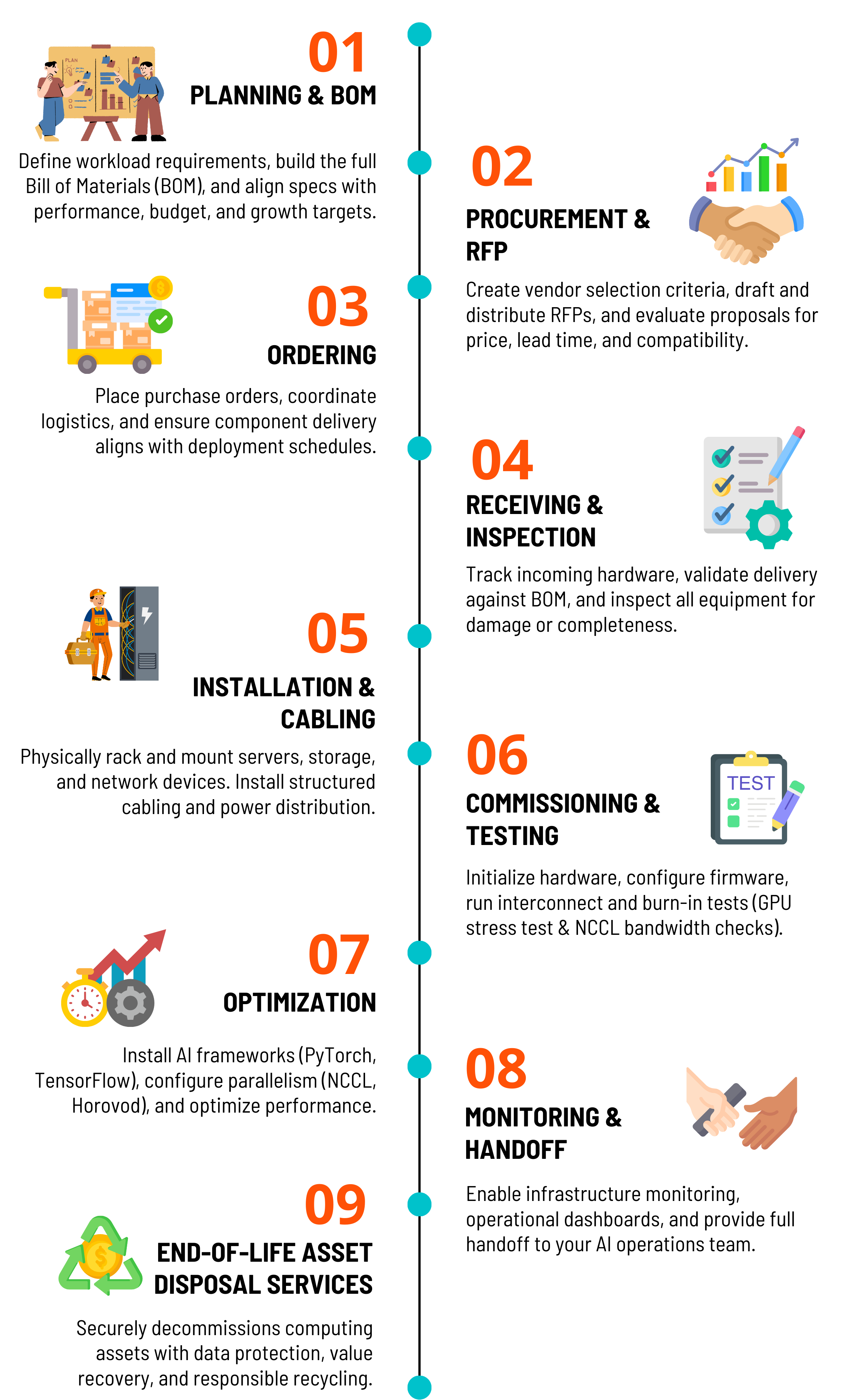
OneSource Cloud designs, deploys, and manages private AI infrastructure - giving organizations full control over their data, hardware, and AI workloads, without the cost unpredictability, compliance risk, or performance limitations of public cloud.

We assess your workloads, security requirements, and growth trajectory to design an AI-ready infrastructure that fits exactly what you need.

We manage procurement, installation, configuration, and cluster setup - delivering a Private AI environment with minimal disruption to your team.

We test everything before we hand it over - and manage it after. Benchmarks, stress tests, and interconnect validation confirm day-one performance. Continuous monitoring and elastic scale whenever your team needs it.
Enterprise-Grade Private AI Infrastructure
Supporting organizations building and scaling Private AI environments.



Practical guidance for secure, reliable, and scalable AI environments
Our blog shares real-world insights on private AI infrastructure, operations, and platform design—based on hands-on experience managing customer-owned systems.
Secure, compliant, and fully managed AI infrastructure—designed for enterprise and regulated environments.

